
04多位点VNTR分析
多位点VNTR分析
多位点VNTR分析(MLVA)是一种基于串联重复序列可变拷贝数(VNTR)对微生物分离株进行亚型分型的分子分型方法。即使在高度相关的细菌菌株中,VNTR通常表现出大拷贝数目的不同。对于一组选定的串联重复序列,拷贝数分析揭示了微观进化关系。
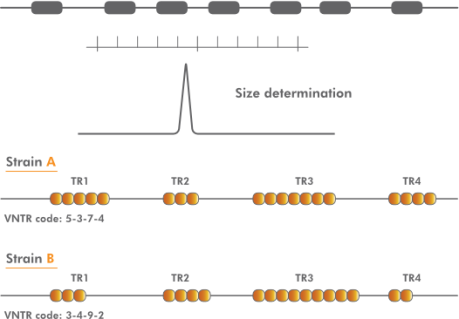
在实践中,选择的VNTR位点对于所研究的生物具有足够的互补性,并且在每个VNTR的串联重复序列外设计保守引物。因此,每个PCR-扩增子的碱基对的大小是串联重复序列的大小加上两端的偏移的总和。
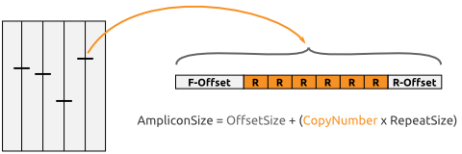
出于经济原因,有时会合并多个VNTR,即用相同的染料标记它们并以混合物的形式装入毛细管测序仪的同一列中。条件是混合的VNTR PCR产物的大小范围不重叠。例如,使用4种染料和2种不重叠的VNTR,每个毛细管电泳可以确定6种VNTR(一种染料包含用于大小计算的参考marker)。
Bionumerics中MLVA分析
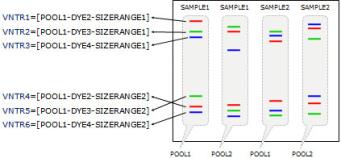
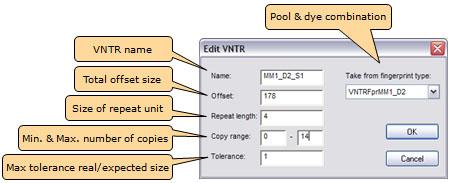
BioNumerics软件提供了用于多位点VNTR分析的全自动工作流程,该流程从原始毛细测序仪图谱文件或预处理峰表(Applied Biosystems和Beckman)开始。最初必须在数据库中输入MLVA设置。这涉及进入样品池的规则:样品池是在同一毛细管中一起加载的VNTR扩增产物的混合物。 这包括使用的不同染料以及(可选)具有不重叠大小范围的兼容VNTR。因此,每个VNTR由池、染料和(可选)大小范围定义。大小范围由重复长度、偏移量和复制范围定义。因此,该软件确切知道应在哪个大小范围内查找特定的VNTR。请注意,复制范围仅在不同的VNTR与同一染料合并的情况下才是必需的。
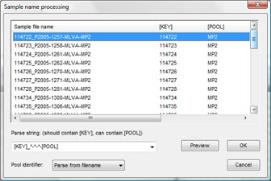 如果是原始色谱图文件(AB,Beckman),则该软件可以使用用户定义的解析字符串从文件名自动解析池、染料和菌株信息。
如果是原始色谱图文件(AB,Beckman),则该软件可以使用用户定义的解析字符串从文件名自动解析池、染料和菌株信息。
对于GeneMapper或Beckman峰表文件,将从制表符分隔的峰表中自动解析此信息(请参见下面的示例)。
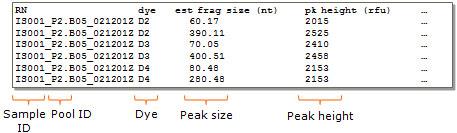
稳健而可靠的方法,与仪器类型无关
由于仪器、染料和毛细管柱的不同,根据拷贝数测得的VNTR扩增子大小通常与理论大小有所不同。因此,可以以bp为单位输入容忍度。显然,容忍度应始终小于RepeatSize / 2。如果重复量较小,则在不同仪器类型之间进行比较时,计算出的拷贝数可能会在系统上不同。为了解决这个问题,BioNumerics提供了创建VNTR映射的方法,即从观察到的大小到每个VNTR和每个VNTR拷贝的实际大小的映射。这种VNTR可确保不同仪器、操作规程、染料、色谱柱等之间的兼容性。
全自动的拷贝数分析
输入VNTR和解析规则的设置后,该软件可以自动处理数千次MLVA运行,从而创建报告,列出未分析的VNTR,发现多个峰以及任何其他问题。报告可以将与期望值的偏差显示为绿色到红色(下面,上面的图像)、左右偏差(蓝色和红色,分别是(中间的图像)或仅错误和警告(下面的图像)。
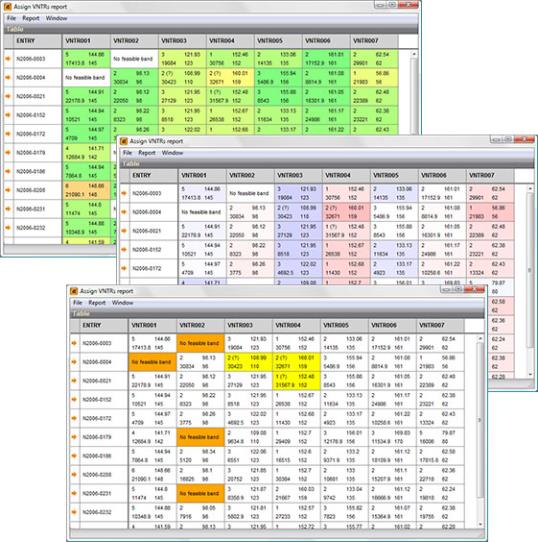
大量的分析工具
所得的VNTR信息存储在整型字符集中,其中每个VNTR代表一个字符。VNTR数据可以分析为分类字符(每个不同的拷贝号是不同的等位基因)或定量字符。在后一种情况下,拷贝数之间的差异越大,则认为生物就越不相关。可以使用当今可用的最精细和最全面的聚类分析应用程序,以微观进化标准作为优先级规则并显示分支重要性支持指标,来计算人口建模网络。已经证明,将最小生成树算法应用于BioNumerics中的VNTR数据对于细菌种群的流行病学研究和种群遗传学具有不可估量的价值。
Bionumerics7.5版本中对MLVA的升级
通过与客户的紧密合作,我们对MLVA插件进行了完全重新设计,以与“曲线处理”窗口无缝集成,“曲线处理”窗口是在7.0版中引入的专用电泳图处理环境。因此有了更灵活的设置和改进的工作流程,从而可以更快,更准确地确定VNTR拷贝数。
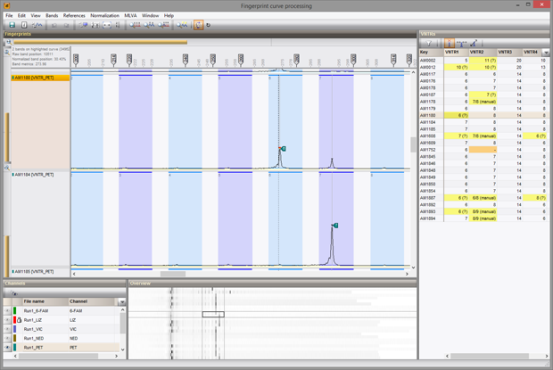
每个数据库轻松设置一个或多个MLVA分析框架
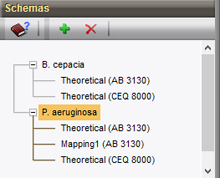
与以前的实现相反,同一数据库中可以使用多个MLVA分析框架。例如,当数据库结合了几个物种的分离株,并且每个物种都有自己的MLVA框架时,这是很有用的。
新的MLVA管理窗口可直接访问所有相关的MLVA设置。基于每个VNTR的重复长度、容忍度和偏移,每个MLVA分析框架都有其理论上的VNTR预测。此外,MLVA分析框架可以具有一个或多个自定义映射,以适应确定片段大小中的偏差。可以通过基于标准化曲线的拖放位置来调整自定义映射。对于使用多个毛细管测序仪的实验室,可以选择定义多种机器类型。
完整的MLVA分析框架可以通过XML文件的导入/导出轻松地进行交换。 这样可以确保不同数据库和使用同一生物的不同研究人员之间的一致性。
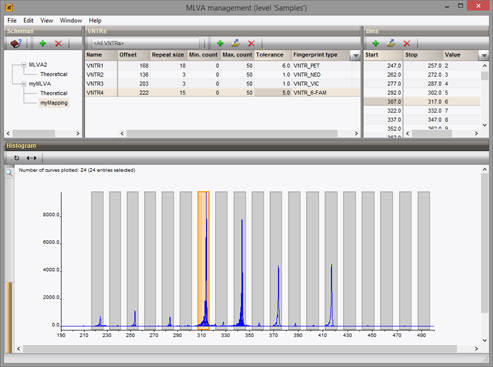
基于MLVA的分型
与MLST类似,分配类型可以极大地促进交流,例如在流行病学研究中。可以基于VNTR的完整集或任何子集来分配MLVA类型和克隆复合体。
为了促进使用统一和稳定的命名法,可以从外部文件或URL导入MLVA类型并使其同步。
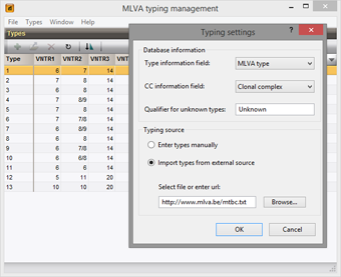
处理双重VNTR分配
在临床样品或某些生物中,观察到双重VNTR等位基因的存在。新的MLVA插件可让您进行此类双重VNTR分配。
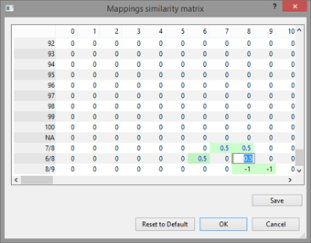
在比较和相似度计算中,通过字符映射相似度矩阵处理双重分配,这是可以由用户来自定义。
增强了电泳图的导入和处理
在BioNumerics 7.5版中,电泳图的导入已集成在常规的导入功能中,从而使其更简便,更灵活。
引入了“曲线处理”窗口中的微小但明显的增强功能,毫无疑问,MLVA用户将从中受益。包括分别用于大小marker和样品的不同组的条带搜索参数,以及选择/取消选择峰的简便方法。


中国区官方授权经销商
以上资料由BioNumerics中国区官方授权经销商独家提供,如需转载请主动标明出处。
客服专线:010-53639817 53639871
市场专线:15712982811 13552183571
QQ客服:3545869936 3316774663
搜索关键词:
比利时Applied-Maths Bionumerics、比利时Bionumerics、BioNumerics生物信息分析软件、BioNumerics生物分析软件、BN分析软件、PFGE分析软件、Bionumerics软件7.6、Bionumerics软件6.6、食源性疾病、