
22Identification projects
Identification projects
Identification can be as quick and simple as sorting a large list of database entries according to similarity with an unknown entry. A more targeted approach is by using an identification project, i.e. a collection of units, each of which consists of one or more entries of the same group (taxon, subtype, variant, serotype, ecotype…). An easy and surveyable identification report lists the identifications obtained by all individual data sets. Mathematical and statistical methods allow the estimation of the reliability and the relevance of each identification case. A detailed pairwise comparison can be obtained between any two entries from the database, which lists all the experiments that both entries share, together with the percentage similarity.
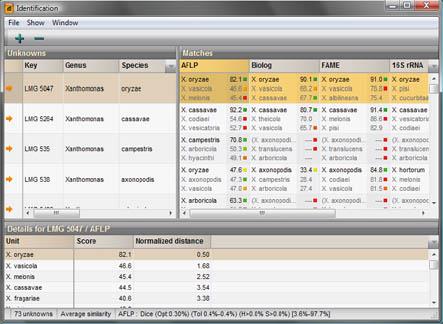
As an interesting alternative to classical similarity-based identification, BioNumerics allows classifiers to be generated for each experiment type. For large databases containing groups that are difficult to distinguish, classifiers can be the quickest and most reliable identification tool.
Required modules:
Classifiers and Identification module
Relevant applications:
MALDI-TOF bacterial identification
See tutorial: